



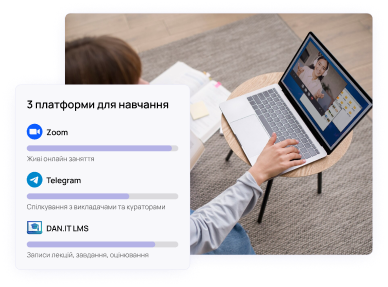
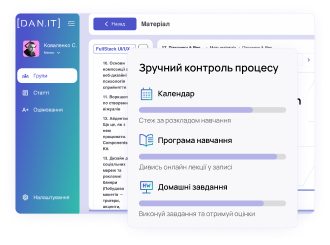


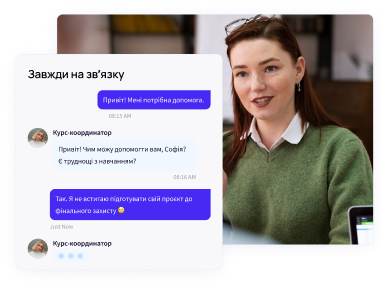




Двухнедельный модуль карьерного сопровождения
-

подготовка резюме и оформление портфолио
-
написание сопроводительного письма
-
оформление профиля в Linkedin
-
пробные собеседования с HR специалистом и техническим экспертом
-
подбор вакансий
-
фидбек после прохождения собеседований и работа над ошибками
-
варианты стажировки в IТ компаниях
-
сопровождение при согласовании оффера и финализации условий труда







